“It all begins and ends in your mind. What you give power to has power over you”
– Leon Brown
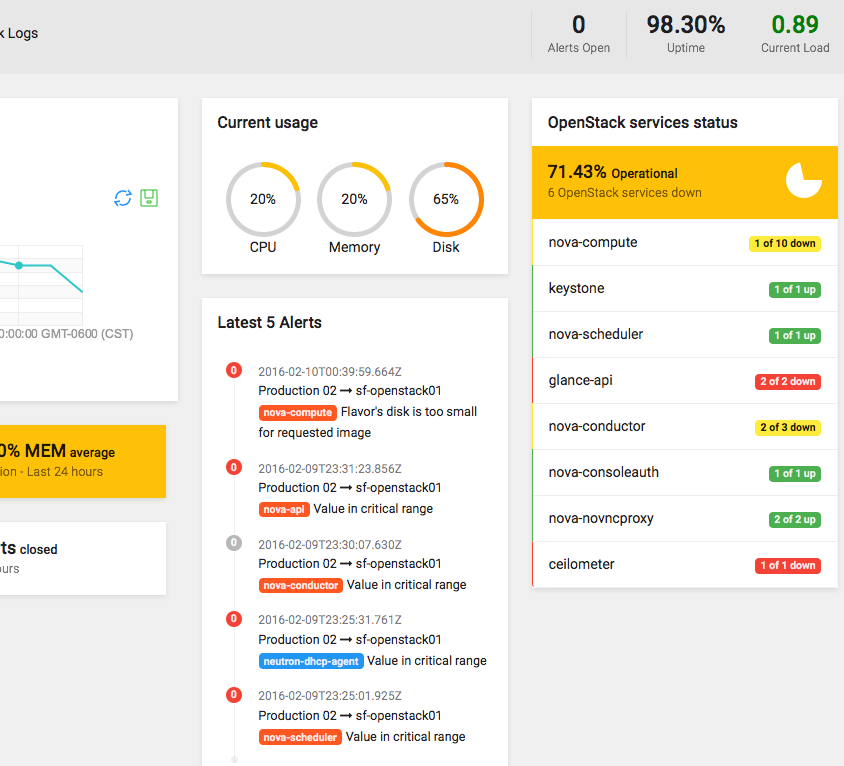
Many users are hanging on your service at this very moment. Users don’t bear failures as much as a couple of seconds to make them start googling other options. You are willing to invest as much as you need to keep them up to your revenue. On other hand, you have to reduce your operation costs to survive.
OpenStack is an amazing start to get agility and savings. Once you have what you need you’d need to keep that up. Rely their performance level on ceilometer and monasca. Both projects bring important features to get the required insight into your app’s infrastructure: memory/cpu usage at every instance, disk capacity/operations at every volume or network traffic.
Ceilometer was the first taste
Projects like heat use ceilometer to trigger additional instances at your service. It brings sweet ways to auto-scale your service depending on customer’s demands. Stay prepared to the unpredictable (check this yaml file out as a good example). It may wake up your hunger for such use cases. Unimaginable ways out of heat may be used thanks to Ceilometer API. Create scripts to automate your apps own your own. Do it with python.
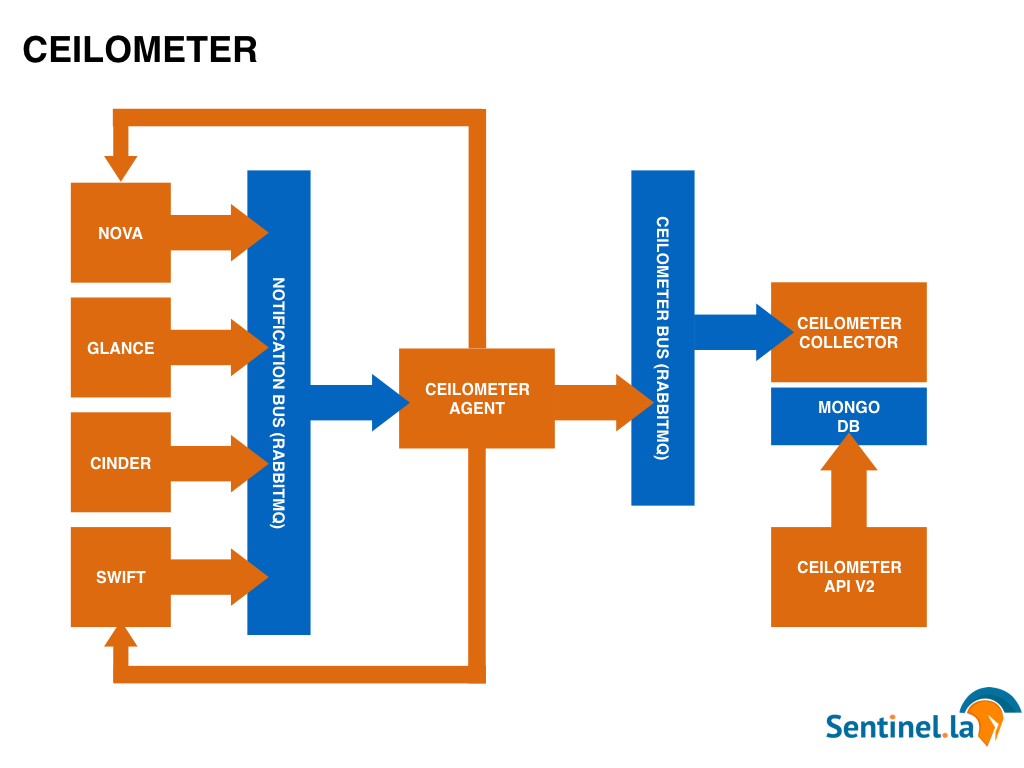
An agent, a Notifications bus, a Collector and MongoDB form what we call Ceilometer. Agent brings metrics from a bunch of projects like nova, glance, swift and cinder. Some projects bring its own through the notification bus (RabbitMQ). Others have to be directly taken through a polling process.

The Collector finally takes the data from the Agent through the Ceilometer bus. MongoDB is storing all what it gets, waiting to be called from the ceilometer API. This API could be called directly to get a better understanding of your platform at this very moment.
However, Ceilometer doesn’t scale at the way you growth and the information that you can get it´s still limited. Also, queries take much time to get them done, which can make your service less responsive to your expectations.
Monasca arose from higher expectations
Monasca bring a multi-tenant monitoring as a service model based on keystone authentication (self-service). A multi-purpose monitoring project, which can look out not only Openstack resources. Efforts can be appreciated into the alarm/thresholding engine. Many plugins available can be easily deployed. Libvirt is an example of them, which helps to get better insight of what is happening inside the hypervisor. It’s already done to run Nagios plugin. System active checks (HTTP, ping, ssh) and response time measures are part its basic features.

An essential element in Monasca is Kafka. Kafka brings a more scalable and faster message queue than RabbitMQ. Monasca use resources like InfluxDB to efficiently store time-series. It brings data retention policies for later analysis and real-time anomaly detection.
Ceilometer and Monasca have teamed into Ceilosca
Ceilosca is a smart combination of the best properties of both projects. Ceilometers is widely used and has an important progress getting metrics from several openstack project. On the other side, Monasca is bringing a scalable way to collect, process and present metrics.
Cisco and HP have joined forces around a project called Ceilosca (ceilometer + monasca). Fabio Giannetti (Cisco) took this to the light in the last summit. He showed how ceilosca has out-performed ceilometer more than 2 or 3 times. How ceilometer degrades depending as many tenant you have. Much less data is being stored through ceilosca for the same amount of queries.

Ceilosca keeps ceilometer to get data´s metrics to the Monasca API. Replacing the Ceilomoter bus and its collector. MongoDB disappears. Monasca API then take the data to Kafka and so on.
Who looks after those who look after themselves?
Simple and powerful question. Ceilometer and Monasca are amazing tools, which are going beyond to just monitor your App’s assets. However, who looks after them. Who looks out those APIs? Are these openstack’s projects actually being monitored? Who looks after their schedulers, processes, logs, files? Who looks after their availability? Who checks if their trustworthy enough to run critical services on top? Is there any single point of failure? Is there any risk to scale-out further to run out of resources? Are my logs or schedulers about to run out of disk? Are their databases resilient enough?
A monitoring service on top monasca could be a good start. Define the metrics and the thresholds. The question is: Do you really have the experience to do that? Do you have enough insight into every openstack’s project? Do you have the time to do that? Wouldn’t it take you so far from your core responsibility?
Would you really trust your OpenStack configuration? Issues into your App resources are easily detected with tools like ceilometer or monasca. However, Issues into Openstack projects could be out of your league. Or, like I’ve just said, It would take you so far of your core business.
I don’t have any doubt you’d have the skills (If you are reading this post at this point, I’m sure you have them). However, your company needs you to look after their apps and services. Not just build and keep openstack up and running.
And we are committed to support you on this duty. And we are sure you’ll find a lot of sense to rely this responsibility on us. Also, you’ll have fun. OpenStack is not an out of the box solution. You won’t find the same configuration twice. Our service just brings the building blocks. And as openstack does, you can take it all, or just take the parts that make you more sense. On one way or the other, you will save a lot of time, And you’ll be having fun creating your own stuff to get more advantage of our service.
Why Sentinel.la is not using Monasca or Ceilometer?
As we’ve told in our previous posts. We are committed to bring a hyper-scalable service. We’ve put also to the on-demand staff pillar as any other ExO.
We’d have liked Monasca to be our platform. However, our core is not to operate Monasca. “Our mission is to help any mortal to unleash OpenStack at every corner of the universe. Help him/her to do it with confidence”. As we expect from our customers to use just the component they like most from our service. We use the components that can get us closer to this mission. Some components like InfluxDB are part of our solution. However, other components like Kafka aren’t.
Besides Kafka, InfluxDB can be contracted and use on demand. Operate and maintain Kafka would take a lot of energy and focus of our development team. Kafka also is developed in Java. That brings another challenge to manage it and operate it. You can’t be expert in every tech. And we’ve decided to stay in python to get more fluency around the openstack community. RabbitMQ can be paid as you go and you can find many options to hire in the market. Our modular design will let us to change any component in the future, even the MQ or the DB, with no disruption.
That’s being said, Monasca API will be supported into our service in the mid-term. You will be able to take/grab system’s data to/from it. You might choose our dashboard/engine to pull some Monasca’s monitored resources (through Monasca API); or just choose Monasca’s alarm/notification engine instead ours. Part of the benefit of being flexible. Don’t you think?