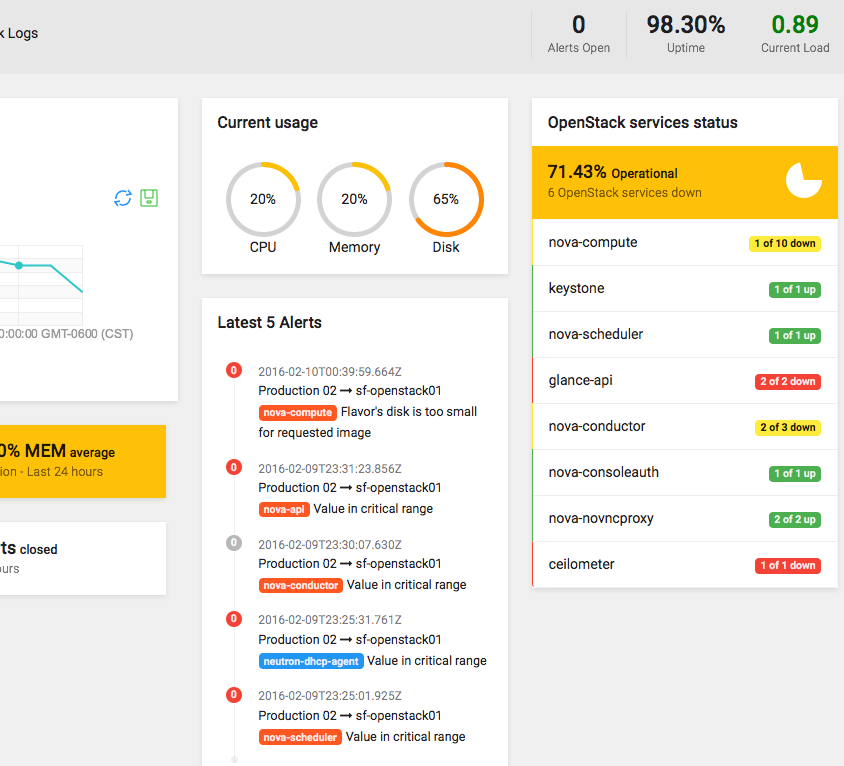
Brand new Sentinel.la plugins to control your entire stack
Sentinel.la is a fast way to manage OpenStack, helping you to reduce OpenStack’s learning curve.
Yes, we do love and specialize on OpenStack, but what happens if you need to do more? If you need help making easier your journey as a DevOps, Sysadmin, Developer or a person interested in getting different data about your server or application, well, we were thinking about it, how can we help you? And then the Plugins idea was born.
The plugins are components in python and with them, you can drop some lines of code with python logic (at this moment) to extract server metrics by processes/components. It’s also possible to monitor within a server and transform it into just one piece of data, for example, the number of volumes in a Docker deployment, Ceph health check, is MySQL server running?, etc.. this information will be displayed into the Sentinella App.
In this way, our users just only get and save the information related to their particular needs.

Sentinel.la is seeking not only into bringing you OpenStack, but to also be an efficient tool. We’ve seen OpenStack deployments that use different components like PostgreSQL, RabbitMQ, Apache, etc.. all that being required to be monitored, to get a faster and better troubleshooting.
This is the reason why now you can make your own plugins and share them with the community.

How do plugins work in Sentinel.la?
Sentinel.la takes your metrics and saves this information using our API, all through Sentinella Agent.
Our components are an abstract of the Sentinel.la functionality to adapt new features.

The plugin uses a task in Sentinella Agent to push new metrics and sends to Sentinella API, when arriving at Sentinella API will apply validation to know if is a valid plugin, the next diagram show you the internal workflow.

Sentinel.la has a process to plugin evaluation, this process starts when registering a plugin release.
Is necessary ensure that all Sentinel.la plugins follow the rules, to keep control and quality this is the reason why we have a process to approving but is simple.
- Register release.
- Evaluatión.
- Approve.
The point 2 consists in the review of code, check if the rules have been applied.
What steps do I need to follow to add my plugin into Sentinel.la?
1.- Register Plugin at Sentinella.
2.- Get your plugin_key.
3.- Download the plugin template.
4.- Put your code logic into your plugin, following the specs.
5.- Make a release.
6.- Install plugin into your server with the Sentinella Agent
For more information click here.
Also, you can take other plugins done by Sentinella Community.
What are the rules?
- Plugins must register into Sentinel.la.
- Follow the documentation to make Sentinel.la Plugin.
- Enjoy.
How do I install a plugin?
Piece of cake:
$ sentinella install <plugin_name> <plugin_version>
How do I configure a plugin?
When the plugin is already installed, open this file /etc/sentinella/sentinella.conf this file has a configuration section for the plugins, it’s one object called plugins.
In this section, you must add your plugin.
Section example:
"plugins": {
"sentinella.openstack_logs": [
"get_openstack_events"
],
"sentinella.metrics": [
"get_server_usage_stats"
],
"sentinella.test": [
"get_stats"
],
"sentinella.sentinella-docker": [ <----- Name of package
"docker_stats" <----- Name method.
]
},
If you have any questions about the package name, class name, etc.. you can go to /usr/share/python/sentinella/lib/python2.7/site-packages/sentinella/ here are all installed plugins.
Doubts?
Please, contact us 🙂