How we built Sentinel.la (II) – AngularJS and Netlify
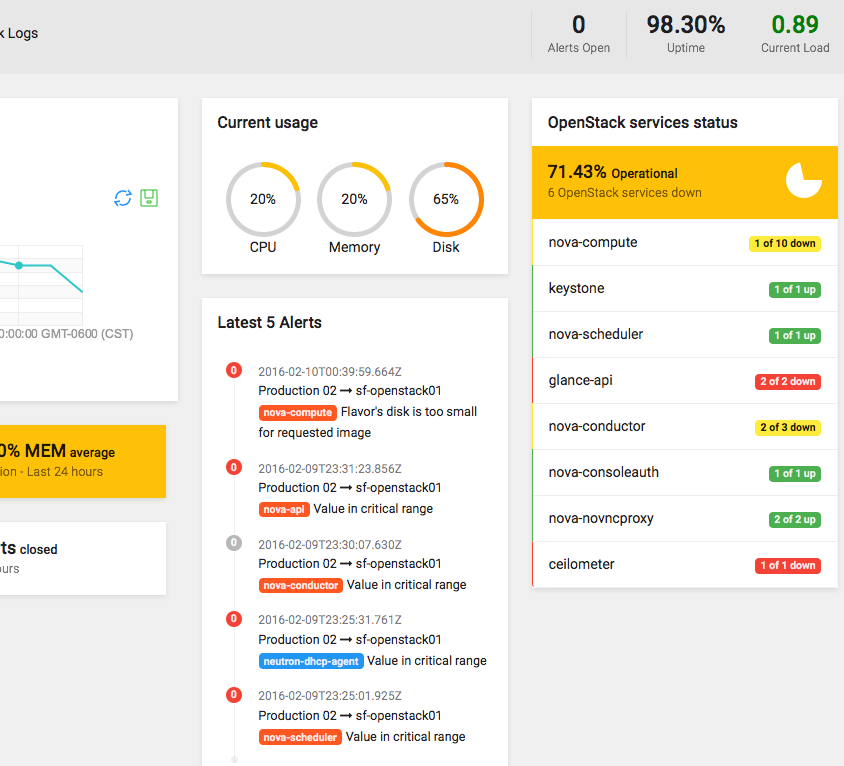
“Apollo” is the codename of our UI. It was built with AngularJS because we wanted a single-page application (SPA). This is how it looks like:

AngularJS and Single-Page Apps.
An SPA ( Single-Page Apps) is a web application (or a website) that fits into a single page in order to give a more seamless experience to users, like a desktop application. Single Page Applications are becoming more popular for a good reason. SPAs can provide an experience that feels almost like a native app in the web, instead of sending a full page of markup, you can send a payload of data and then turn it into markup at the client side.
We decided to build an hybrid SPA. By hybrid I mean that, instead of treating the entire application as a single page application, we divide it into logical units of work or paths through the system. You end up with certain areas that result in a full page refresh, but the key interactions of a module take place in the same page without refreshing. For example, administration might be one “mini” SPA app while configuration is another.
Another advantage of AngularJS is that it uses the MVC approach, which is familiar to developers who have used Django or another MVC web development framework. Angular implements MVC by asking you to split your app into MVC components, then Angular manages those components for you and also serves as the pipeline that connects them.
Another advantage is that it puts the DOM manipulations where they belong. Traditionally, the view modifies the DOM to present data and manipulates the DOM (or invokes jQuery) to add behavior. With Angular, DOM manipulation code should be inside directives and not in the view. Angular takes the view just as another HTML page with placeholders for data.
Every SPA needs an API to consume. We built an API with Flask, that I’ll be reviewing in further posts,

Do not handle webservers, JAM Stack and Netlify.
Once we finished the UI and the API, we launched it over an nginx web servers farm. Also we decided to use a CDN to improve user experience in terms of speed and also to help us prevent site crashes in the event of traffic usage peaks. So, in this case, the CDN would help us to distribute bandwidth across multiple servers, instead of having to use just one server handling all the traffic.
While searching the internet looking for a good and affordable CDN we discovered Netlify and the JAMStack.
“JAM stands for JavaScript, APIs and Markup. It’s the fastest growing stack for building websites and apps: no more servers, host all your front-end on a CDN and use APIs for any moving parts[…] The JAMstack uses markup languages like HTML, CSS and Markdown to format and style our content, client-side Javascript to make it interactive and engaging and APIs to add persistence, real-time sync, real-world interactions, comments, shopping carts, and so on.“ – https://jamstack.org/
“Netlify is a unified platform that automates your code to create high-performant, easily maintainable sites and web apps” . – https://www.netlify.com/

So, we decided to use Netlify. It allow us to bring an automated platform to deploy our AngularJS app, because it follows the JAMStack, and also provide us with the best practices like CDN distribution, caching and continuous deployment with a single click – or command. That means not handling webservers, therefore less effort and work. For a startup like us that’s very valuable.
With Netlify we just push our site to their CDN because it pairs naturally with Git. That’s why you only need to pull, change and push the code to manage your site. After a git push, the newest version is immediately available everywhere and with their integrations you can set up any number of outbound webhooks so you can receive an e-mail or Slack notifications to notify for deploy information or build failures.
Netlify has a lot of features like DDoS protection, Snapshots, Versioning & Rollbacks, Instant Cache Invalidation, DNS Hosting, Domain Registration, etc. You can check more Netlify features here: https://www.netlify.com/features/
In the next post I’ll review the API and the AMQP topics about how we built our Software. Stay tuned.